


嗨。我是IDG的Sharon Machlis,这里是《用R做更多:3种方式连接数据库R、tidyverse和data.table》的第38集。
这里,通过连接数据,我的意思是通过一个或多个公共列组合两个数据帧。而不仅仅是添加额外的行。
在这个例子中,我将使用我最喜欢的一个数据集——航班延误时间。如果你想跟我去,那就去the bit吧。屏幕上的ly链接(bit . ly斜线usflightdelay),并下载带有航班日期、Reporting_Airline、出发地、目的地和出发时间列的数据。还可以获得Reporting_Airline的查找表。
你可以在我相关的InfoWorld文章中找到所有的代码和数据下载链接,网址在屏幕上。
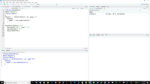
让我们开始吧。首先让我读一下这两个文件,基本的R方式。我首先解压缩航班延误文件,然后用read.csv导入延误和代码查找文件。
让我们看一下这两个数据帧。
我想在航班延误数据中添加一列航空公司名称。基本的方法是使用merge()函数。
合并的语法是第一数据帧,第二数据帧。如果你想要加入by的列没有相同的名字,你需要告诉merge你想要加入哪些列:by。为x数据帧列名,by。y代表y 1。
您还可以告诉merge是否需要所有的行,包括那些没有匹配的行,或者只需要匹配的行。在本例中,我想要延迟数据中的所有行—如果查找表中没有航空公司代码,我仍然需要这些信息。但是我不需要查找表中不存在延迟数据的行(有一些旧航空公司的代码已经不在那里飞行了)。因此,所有。x等于TRUE。y = FALSE。让我运行一下
您现在可以看到,我的连接数据框架包括一个名为“Description”的列,其中包含基于承运人代码的航空公司名称。我的新数据帧的行数与我的初始延迟数据帧的行数相同,所以我没有遗漏任何东西。
接下来,让我们看看tidyverse dplyr连接。Dplyr对其连接函数使用SQL数据库语法。
“左联接”意味着包括左边的所有内容(merge()中的x数据帧是什么)以及与右边(或y)数据帧匹配的所有行。如果join列有相同的名称,那么您需要的只是left_join(x, y),如果它们没有相同的名称,那么您需要一个by参数。注意这里的语法:它是一个向量:左数据框列名等于右数据框列名,两个名称都用引号括起来。
现在用R表示。
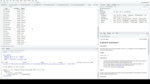
我将加载dplyr和readr包,然后用read_csv读取这两个文件。使用read_csv,我不需要先解压缩文件。
Read_csv创建了一个tibble,这是一种带有一些额外特性的数据框架类型。
我将使用left_join()来连接这两个小块。看一下语法。这一次,顺序很重要。提示:left_join意味着包含左边或第一个数据集的所有行,但只包含与第二个数据集匹配的行。我需要连接两个不同命名的列,我有一个by参数。
这个连接的数据集现在有一个新的列,列的名称是航空公司。你可能注意到这比以R为底要快得多。
现在,让我们来看看一种超级快速的方法来处理这些数据。表方案。
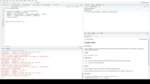
这里我加载数据。表,然后使用数据。表的fread()函数来导入zip文件。
为了读取压缩的文件,我使用fread的功能来直接调用shell命令。这就是解压缩cq部分的作用。fread()创建一个数据。表对象——具有额外功能的数据框架。
至少有两种方法可以使用data.table进行连接。一个是使用与基本r完全相同的merge()语法。它的工作方式是相同的,但是要快得多。
如果你想使用数据。表语法,您可以首先使用setkey()函数来设置要联接的列。然后,语法是—正如您在最后一行代码中看到的—查找表(或右数据帧—不需要所有行,只需要匹配的行)、左方括号、带数据的表、右方括号
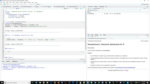
最后,我将为那些喜欢dplyr语法,或者习惯于SQL数据库语法,但是需要快速数据的人演示一个包。表后端。这在新的dtplyr 1.0包中是可能的。
按照通常的方式安装和加载包。要使用dtplyr,您需要将数据帧或tibbles转换成特殊的惰性数据表对象。使用dtplyr的lazy_dt()函数可以做到这一点。我在这里的第一组代码中做了这个工作,将read_csv的结果输送到lazy_dt()函数。
现在我可以用通常的方法把这两个物体连接起来。我得到的是一个特殊的dtplyr step对象
。如果我把它打印出来,你可以看到数据。创建对象的表代码。这很方便!我还看到了数据的前几行,以及将该对象转换为数据帧、tibble或数据所需的消息。如果我想使用里面的数据。
在运行了一些相当粗糙的基准测试之后,这两个数据。表方法是最快的;dtplyr几乎同样快;dplyr花了大约两倍的时间;以R为底会慢15到20倍。这里需要特别注意的是,性能取决于数据集的结构和大小,并且可能因任务的不同而有很大差异。但是可以肯定地说,除了小数据帧外,base R并不是一个很好的选择。
概括一下:下面的代码通过一个公共列合并两个数据帧,在这个公共列中,您希望第一个(或左)数据集的所有行都与另一个数据集中的行匹配。这是基本R或data.table的语法。
这是dplyr的语法。这是数据的语法。表(请记住,您也可以使用merge())。数据还有另一种语法。不需要单独的setkey()语句的表。我不使用它,但如果你更喜欢它,这里是:在括号中添加一个on参数。
如果只想要匹配的行呢?这是内连接。
用于基本R或数据的merge()语法。表都是。x和。y都假的。对于dplyr,使用inner_join()。和数据。除了merge()之外,表语法也可以是这样的(我没有使用setkey()命令,因为我已经为该数据设置了键)。
如果您想要查看左(或x)数据集中不存在匹配的行,这就是反连接。在左或内连接之后运行它来查看哪些内容不匹配是非常有用的—有时您期望没有匹配,但其他时候则没有。
我可能会使用来自dplyr的anti_join()或者来自数据的dt括号语法。表。
如果您想要来自两个数据集的所有行,而不管是否匹配,这就是完全连接。为此,我通常使用merge()和all equals true,或者使用dplyr full_join。
最后,我经常遇到的一个问题是:两列连接怎么样?让我来具体说明一下,你可以在InfoWorld的相关文章中下载所有的代码和这个幻灯片。
对于多列上的merge(),您可以创建一个常规的x列名向量,每个列名都用引号括起来;和一个常规的y列向量,也都是用引号括起来的。如果两个数据集中的列名相同,就不需要指定它们,但我通常喜欢这样做,以防止意外的事情发生。dplyr语法略有不同,更像是SQL。它表示哪些列等于哪些列。在这里,ZipCode应该与zip匹配,等等。这是相关文章中的另一个例子。
数据。表有两种方法来设置一个数据集中的多个键。setkey()引用列名不加引号;setkeyv,如果你想在矢量中引用名字。
也有数据。表上的参数。所有这些语法只是哦,所以略有不同,我的建议是选择一种方式,并坚持它…或者把它们都放在一个容易拿到的地方。
再一次,你可以下载我的幻灯片和这个视频的代码在这个屏幕上的URL。
这一集就到这里,感谢收看!要了解更多关于R的技巧,请前往go。infoworld。com网站上的“用R做更多”页面,除R外其他字母都是小写的。
你也可以在YouTube IDG技术谈话频道上找到“用R做更多”的播放列表——在那里你可以订阅,这样你就不会错过任何一集。希望下次能见到你!
这里,通过连接数据,我的意思是通过一个或多个公共列组合两个数据帧。而不仅仅是添加额外的行。
在这个例子中,我将使用我最喜欢的一个数据集——航班延误时间。如果你想跟我去,那就去the bit吧。屏幕上的ly链接(bit . ly斜线usflightdelay),并下载带有航班日期、Reporting_Airline、出发地、目的地和出发时间列的数据。还可以获得Reporting_Airline的查找表。
你可以在我相关的InfoWorld文章中找到所有的代码和数据下载链接,网址在屏幕上。
让我们开始吧。首先让我读一下这两个文件,基本的R方式。我首先解压缩航班延误文件,然后用read.csv导入延误和代码查找文件。
让我们看一下这两个数据帧。
我想在航班延误数据中添加一列航空公司名称。基本的方法是使用merge()函数。
合并的语法是第一数据帧,第二数据帧。如果你想要加入by的列没有相同的名字,你需要告诉merge你想要加入哪些列:by。为x数据帧列名,by。y代表y 1。
您还可以告诉merge是否需要所有的行,包括那些没有匹配的行,或者只需要匹配的行。在本例中,我想要延迟数据中的所有行—如果查找表中没有航空公司代码,我仍然需要这些信息。但是我不需要查找表中不存在延迟数据的行(有一些旧航空公司的代码已经不在那里飞行了)。因此,所有。x等于TRUE。y = FALSE。让我运行一下
您现在可以看到,我的连接数据框架包括一个名为“Description”的列,其中包含基于承运人代码的航空公司名称。我的新数据帧的行数与我的初始延迟数据帧的行数相同,所以我没有遗漏任何东西。
接下来,让我们看看tidyverse dplyr连接。Dplyr对其连接函数使用SQL数据库语法。
“左联接”意味着包括左边的所有内容(merge()中的x数据帧是什么)以及与右边(或y)数据帧匹配的所有行。如果join列有相同的名称,那么您需要的只是left_join(x, y),如果它们没有相同的名称,那么您需要一个by参数。注意这里的语法:它是一个向量:左数据框列名等于右数据框列名,两个名称都用引号括起来。
现在用R表示。
我将加载dplyr和readr包,然后用read_csv读取这两个文件。使用read_csv,我不需要先解压缩文件。
Read_csv创建了一个tibble,这是一种带有一些额外特性的数据框架类型。
这个连接的数据集现在有一个新的列,列的名称是航空公司。你可能注意到这比以R为底要快得多。
现在,让我们来看看一种超级快速的方法来处理这些数据。表方案。
这里我加载数据。表,然后使用数据。表的fread()函数来导入zip文件。
为了读取压缩的文件,我使用fread的功能来直接调用shell命令。这就是解压缩cq部分的作用。fread()创建一个数据。表对象——具有额外功能的数据框架。
至少有两种方法可以使用data.table进行连接。一个是使用与基本r完全相同的merge()语法。它的工作方式是相同的,但是要快得多。
如果你想使用数据。表语法,您可以首先使用setkey()函数来设置要联接的列。然后,语法是—正如您在最后一行代码中看到的—查找表(或右数据帧—不需要所有行,只需要匹配的行)、左方括号、带数据的表、右方括号
最后,我将为那些喜欢dplyr语法,或者习惯于SQL数据库语法,但是需要快速数据的人演示一个包。表后端。这在新的dtplyr 1.0包中是可能的。
按照通常的方式安装和加载包。要使用dtplyr,您需要将数据帧或tibbles转换成特殊的惰性数据表对象。使用dtplyr的lazy_dt()函数可以做到这一点。我在这里的第一组代码中做了这个工作,将read_csv的结果输送到lazy_dt()函数。
现在我可以用通常的方法把这两个物体连接起来。我得到的是一个特殊的dtplyr step对象
在运行了一些相当粗糙的基准测试之后,这两个数据。表方法是最快的;dtplyr几乎同样快;dplyr花了大约两倍的时间;以R为底会慢15到20倍。这里需要特别注意的是,性能取决于数据集的结构和大小,并且可能因任务的不同而有很大差异。但是可以肯定地说,除了小数据帧外,base R并不是一个很好的选择。
概括一下:下面的代码通过一个公共列合并两个数据帧,在这个公共列中,您希望第一个(或左)数据集的所有行都与另一个数据集中的行匹配。这是基本R或data.table的语法。
这是dplyr的语法。这是数据的语法。表(请记住,您也可以使用merge())。数据还有另一种语法。不需要单独的setkey()语句的表。我不使用它,但如果你更喜欢它,这里是:在括号中添加一个on参数。
如果只想要匹配的行呢?这是内连接。
用于基本R或数据的merge()语法。表都是。x和。y都假的。对于dplyr,使用inner_join()。和数据。除了merge()之外,表语法也可以是这样的(我没有使用setkey()命令,因为我已经为该数据设置了键)。
如果您想要查看左(或x)数据集中不存在匹配的行,这就是反连接。在左或内连接之后运行它来查看哪些内容不匹配是非常有用的—有时您期望没有匹配,但其他时候则没有。
我可能会使用来自dplyr的anti_join()或者来自数据的dt括号语法。表。
如果您想要来自两个数据集的所有行,而不管是否匹配,这就是完全连接。为此,我通常使用merge()和all equals true,或者使用dplyr full_join。
最后,我经常遇到的一个问题是:两列连接怎么样?让我来具体说明一下,你可以在InfoWorld的相关文章中下载所有的代码和这个幻灯片。
对于多列上的merge(),您可以创建一个常规的x列名向量,每个列名都用引号括起来;和一个常规的y列向量,也都是用引号括起来的。如果两个数据集中的列名相同,就不需要指定它们,但我通常喜欢这样做,以防止意外的事情发生。dplyr语法略有不同,更像是SQL。它表示哪些列等于哪些列。在这里,ZipCode应该与zip匹配,等等。这是相关文章中的另一个例子。
数据。表有两种方法来设置一个数据集中的多个键。setkey()引用列名不加引号;setkeyv,如果你想在矢量中引用名字。
再一次,你可以下载我的幻灯片和这个视频的代码在这个屏幕上的URL。
这一集就到这里,感谢收看!要了解更多关于R的技巧,请前往go。infoworld。com网站上的“用R做更多”页面,除R外其他字母都是小写的。
你也可以在YouTube IDG技术谈话频道上找到“用R做更多”的播放列表——在那里你可以订阅,这样你就不会错过任何一集。希望下次能见到你!











受欢迎的
IDG.tv的特色视频