


如何搜索Twitter有R
信息世界|2020年1月23日
了解如何搜索,筛选和排序鸣叫使用R和rtweet包。这是按照会议主题标签的好方法。如果你想创建可点击的URL链接选项码沿着沿,确保安装purrr包,如果它不是已经在你的系统上。
版权©2020Raybet2
类似
你好。我莎朗马克利斯在IDG,这里做一集41多与R:跟踪Twitter的#标签。
Twitter是一个很好的R新闻来源——特别是在用户会议和RStudio会议期间。多亏了R和rtweet包,我可以构建自己的工具来下载tweet,以便于搜索、排序和过滤。让我们一步一步来看看。
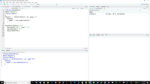
首先要安装并加载任何项目的包你不已经有:rtweet,反应性,胶水,stringr,httpuv和dplyr。然后启动,负载rtweet和dplyr。
要使用rtweet,你需要一个Twitter帐户,因为你需要授权rtweet使用特定帐户凭据。这是因为有多少鸣叫,你可以在15分钟的时间内下载的限制。迈克尔·科尔尼,谁写rtweet,为我们提供了两种选择。超级简单的方法是只要求一些鸣叫。如果你不具备任何存储凭据,浏览器窗口会弹出要求您授权请求。在此之后,授权令牌获取存储在您的[R环境文件,这样就不必在未来重新检查!(你可以去rtweet.info看到其他方式,这是建立一个开发项目,并获得授权证书。如果你打算使用rtweet了很多,你可能会想这样做)。但就目前而言,最简单的方式!我将显示一分钟。
要搜索带有特定hashtag的tweet,可以使用(名称非常直观)search_tweets()函数。它需要一些参数。首先是查询:类似于#rstudioconf, #useR2020, #rstats。其次是你想要返回的tweet的数量。默认为100。但是,关于通过关键字搜索tweet,还有一件重要的事情你需要知道:不幸的是,搜索只会返回到6到9天左右,除非你支付了一个高级的Twitter API帐户。您不能使用rtweet来搜索今天的消息并查找去年的RStudio会议消息。会议结束两周后,你将无法搜索到这些推文。所以你要确保你将来想要的那些旧的。
另一个search_tweets()的参数是你是否要包括锐推。对于我的目的,我没有,所以我设置为FALSE。
还有,你可以用它来定制搜索更多的参数,但现在让我们做一个基本的搜索:200个鸣叫与#rstudioconf#标签。见多么容易的授权是?而rtweet在我的[R环境文件自动保存一个道理,所以我不会需要在将来再次授权。
现在让我们看看结果。
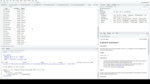
我突然想到几件事。一个是:我要求了200条推文,但得到的回复更少。有几个可能的原因。一个是在过去的6-9天里可能不会有200条tweet,因为我是在今年的会议开始之前运行这些代码的。另一个原因是,Twitter最初可能提取了200条tweet,但在过滤掉retweet之后,剩下的就更少了。
你可能已经注意到的另一件事是:每个tweet有90列数据!这是很多的度量标准。我们来看看这些这些是列名。
我最感兴趣的通常是status_id、created_at、screen_name、text、favorite_count、retweet_count和urls_expanded_url。您可能需要一些其他的列来进行分析;但在这个演示中,我只选择这些列。这将使数据在屏幕上更容易看到。
所以这是第1部分:获得首批鸣叫。第2步是做与他们的东西。
有很多有趣的可视化和分析,你可以与Twitter数据和R.其中一些被内置到rtweet做。但是我在做这个演示穿着我的技术新闻工作者的帽子。我希望有一个简单的方法来看到新的和凉的东西我可能不知道的。所以,我想看到的一些最喜欢的鸣叫从会议。由于R,我没有依靠Twitter的“流行”的算法。我可以做我自己的搜索和设定自己的标准,“流行”。只是“今天”也许寻找顶部的鸣叫,而会议正在进行中。或特定主题我很感兴趣,像“闪亮”或“purrr”,由最喜欢或最锐推来分类的过滤器。
一个做这类搜索和排序的最简单的方法是用一个排序表。DT是一个流行的包这一点。但最近我一直在尝试用另一个:反应性。
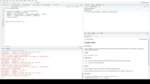
默认的反应性()是一种嗒嗒的。我想出了一套自己的默认值,我通常添加到表中。让我走了这些。
过滤将每个列标题下的搜索过滤器。检索增加了一个整体表搜索框,搜索所有列。打开接壤,条纹和亮点做了你所期望的:增加了一个表格边框,增加了交行的颜色“条纹”,并强调如果你把光标放在它的行。showSortable增加了小箭头图标旁边的列名,以便用户知道他们可以点击排序。我把我的defaultPageSize至25 showPageSizeOptions让我改变页面长度交互,然后我定义页面大小选项,将在下拉菜单中显示出来。最后,我每个defaultSortOrder设置为下降,而不是上升。如果我点击锐推或喜欢的号码,我希望看到,作为“多到少”,并非最不重要的大多数。
最后,还有列的说法。这是一个包含每个列的列定义列表清单。看更多细节能够反应的帮助文件,但在这里我设置了几个列有一个默认的排序顺序递增。对于文本列,我希望它显示HTML作为HTML,所以我可以添加可点击的链接;我想设置在像素列的最小宽度;和我做它可调整大小的 - 这样我就可以点击并拖动,使其变宽或变窄。我关掉过滤器盒FAVORITE_COUNT和REPLY_COUNT。这是因为不幸的是,反应性过滤器不明白,那些列数,并且将它们过滤器字符串。别担心:反应性排序的列数正确,它只是这些过滤器的箱子,是一个问题。这是对反应的主要缺点与DT包进行比较。 But sorting numerically is enough for me for this purpose. So let’s go back and see what that looks like.
如果我点击favorite_count列,我可以看到最喜欢的。
我可以点击并在鸣叫文本列拖使其变宽或变窄。
有几件事会使它更有用。我决定不在tweet文本字段中显示图像或视频,因为我在这里的目的是扫描文本。但是有时候看到原始的推文是有帮助的。所以我为添加到tweets中的url创建了一个单独的列。通过这种方式,我可以很容易地过滤包含url的tweet。如果我试图找到带有演示文稿或资源链接的tweet,这就很方便了。但是现在,我不能点击去看任何东西。我需要在我的R代码中创建可点击链接的HTML。
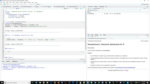
因此,让我回到我的微博数据帧,并做到这一点。作为提醒,下面是选择列我的表的代码。现在让我来添加列与HTML。对于鸣叫的文字,我想在最后添加一个小东西可点击这里我可以点击查看Twitter上的实际鸣叫。我决定在“空间大于-SIGN大超征”,虽然它可以是任何一个或多个字符。
如果我看一下推特的格式。看到tweet URL的格式了吗?它是twitter。com /用户名/状态/推文ID。用胶水,那就是这里的代码。如果您以前没有使用过glue,那么它是一个将文本和变量值粘贴在一起的好工具。使用一个带引号的表达式,并将希望计算的任何变量名放在大括号中。
的代码的第一行创建从状态ID和用户名的鸣叫的链接。下一行创建TweetLink,是空间大于大于链接。然后最后我创建了一条Twitter消息列包含可点击的链接。
最后,在那之后我做一个快速反应的只有新资料Tweet列来检查我的链接。有用!你可以做类似的标记网址列可点击的东西,虽然我不会是演示,以节省一点时间。
现在我将合并我的代码,这样我就不会为一条tweet创建三个新列(我这样做只是为了更容易地解释和显示代码)。我将重命名我的列,使它们更加用户友好,并生成我的最终表。
总结一下:这里我用我想要的数据从原始的tweet数据框架创建了一个新的数据框架。我正在选择一些列,然后添加推文列与可点击的链接在最后,然后选择和重命名一些列。这是我的代码,使可点击的链接从URL列。我就不详细讲了,但是你们可以暂停视频来看看。或者,点击与本视频相关的文章,这样你就可以复制和粘贴代码了。它比你想象的要复杂一些因为这一列是一个列表列;有些tweet包含多个URL。
这是我的带reactable的格式化表格。数据帧是我的第一个参数。其余部分主要是格式化和表行为。
将所有这些代码放到一个脚本中并运行它,您就得到了一个可搜索的会议标签数据库!
有一点要记住:如果您在会议期间遵从会议主题标签,你想拉足够的鸣叫让整个会议。因此,检查您的鸣叫数据帧的最早日期。如果该日期是会议开始后,要求更多的鸣叫。如果您的会议包括hashtag拥有超过18,000鸣叫 - 当我正在跟踪的消费电子展的事情发生了 - 你需要想出一些策略来获得整个集。检查出search_tweets的retryonratelimit()的参数,如果你想收集整套会议包括hashtag鸣叫追溯到6天或更少。
最后,确保在会议结束时将数据保存到本地文件中。一周后,您将不再能够通过search_tweets()和Twitter API访问这些tweet。
在奖金的文章和视频,我将演示如何把它变成一个互动的闪亮的应用程序。
这是它为这个情节,感谢收看!对于以上R提示,头向做多有R一页位点-LY削减有R做多,全部小写除了R.你也可以找到做多配合YouTube IDG技术讲座槽R播放列表 -- 在这里你可以订阅,所以你永远不会错过任何一集。希望下次再见!
Twitter是一个很好的R新闻来源——特别是在用户会议和RStudio会议期间。多亏了R和rtweet包,我可以构建自己的工具来下载tweet,以便于搜索、排序和过滤。让我们一步一步来看看。
首先要安装并加载任何项目的包你不已经有:rtweet,反应性,胶水,stringr,httpuv和dplyr。然后启动,负载rtweet和dplyr。
要使用rtweet,你需要一个Twitter帐户,因为你需要授权rtweet使用特定帐户凭据。这是因为有多少鸣叫,你可以在15分钟的时间内下载的限制。迈克尔·科尔尼,谁写rtweet,为我们提供了两种选择。超级简单的方法是只要求一些鸣叫。如果你不具备任何存储凭据,浏览器窗口会弹出要求您授权请求。在此之后,授权令牌获取存储在您的[R环境文件,这样就不必在未来重新检查!(你可以去rtweet.info看到其他方式,这是建立一个开发项目,并获得授权证书。如果你打算使用rtweet了很多,你可能会想这样做)。但就目前而言,最简单的方式!我将显示一分钟。
要搜索带有特定hashtag的tweet,可以使用(名称非常直观)search_tweets()函数。它需要一些参数。首先是查询:类似于#rstudioconf, #useR2020, #rstats。其次是你想要返回的tweet的数量。默认为100。但是,关于通过关键字搜索tweet,还有一件重要的事情你需要知道:不幸的是,搜索只会返回到6到9天左右,除非你支付了一个高级的Twitter API帐户。您不能使用rtweet来搜索今天的消息并查找去年的RStudio会议消息。会议结束两周后,你将无法搜索到这些推文。所以你要确保你将来想要的那些旧的。
另一个search_tweets()的参数是你是否要包括锐推。对于我的目的,我没有,所以我设置为FALSE。
还有,你可以用它来定制搜索更多的参数,但现在让我们做一个基本的搜索:200个鸣叫与#rstudioconf#标签。见多么容易的授权是?而rtweet在我的[R环境文件自动保存一个道理,所以我不会需要在将来再次授权。
现在让我们看看结果。
我突然想到几件事。一个是:我要求了200条推文,但得到的回复更少。有几个可能的原因。一个是在过去的6-9天里可能不会有200条tweet,因为我是在今年的会议开始之前运行这些代码的。另一个原因是,Twitter最初可能提取了200条tweet,但在过滤掉retweet之后,剩下的就更少了。
你可能已经注意到的另一件事是:每个tweet有90列数据!这是很多的度量标准。我们来看看这些这些是列名。
我最感兴趣的通常是status_id、created_at、screen_name、text、favorite_count、retweet_count和urls_expanded_url。您可能需要一些其他的列来进行分析;但在这个演示中,我只选择这些列。这将使数据在屏幕上更容易看到。
所以这是第1部分:获得首批鸣叫。第2步是做与他们的东西。
有很多有趣的可视化和分析,你可以与Twitter数据和R.其中一些被内置到rtweet做。但是我在做这个演示穿着我的技术新闻工作者的帽子。我希望有一个简单的方法来看到新的和凉的东西我可能不知道的。所以,我想看到的一些最喜欢的鸣叫从会议。由于R,我没有依靠Twitter的“流行”的算法。我可以做我自己的搜索和设定自己的标准,“流行”。只是“今天”也许寻找顶部的鸣叫,而会议正在进行中。或特定主题我很感兴趣,像“闪亮”或“purrr”,由最喜欢或最锐推来分类的过滤器。
一个做这类搜索和排序的最简单的方法是用一个排序表。DT是一个流行的包这一点。但最近我一直在尝试用另一个:反应性。
默认的反应性()是一种嗒嗒的。我想出了一套自己的默认值,我通常添加到表中。让我走了这些。
过滤将每个列标题下的搜索过滤器。检索增加了一个整体表搜索框,搜索所有列。打开接壤,条纹和亮点做了你所期望的:增加了一个表格边框,增加了交行的颜色“条纹”,并强调如果你把光标放在它的行。showSortable增加了小箭头图标旁边的列名,以便用户知道他们可以点击排序。我把我的defaultPageSize至25 showPageSizeOptions让我改变页面长度交互,然后我定义页面大小选项,将在下拉菜单中显示出来。最后,我每个defaultSortOrder设置为下降,而不是上升。如果我点击锐推或喜欢的号码,我希望看到,作为“多到少”,并非最不重要的大多数。
最后,还有列的说法。这是一个包含每个列的列定义列表清单。看更多细节能够反应的帮助文件,但在这里我设置了几个列有一个默认的排序顺序递增。对于文本列,我希望它显示HTML作为HTML,所以我可以添加可点击的链接;我想设置在像素列的最小宽度;和我做它可调整大小的 - 这样我就可以点击并拖动,使其变宽或变窄。我关掉过滤器盒FAVORITE_COUNT和REPLY_COUNT。这是因为不幸的是,反应性过滤器不明白,那些列数,并且将它们过滤器字符串。别担心:反应性排序的列数正确,它只是这些过滤器的箱子,是一个问题。这是对反应的主要缺点与DT包进行比较。 But sorting numerically is enough for me for this purpose. So let’s go back and see what that looks like.
如果我点击favorite_count列,我可以看到最喜欢的。
有几件事会使它更有用。我决定不在tweet文本字段中显示图像或视频,因为我在这里的目的是扫描文本。但是有时候看到原始的推文是有帮助的。所以我为添加到tweets中的url创建了一个单独的列。通过这种方式,我可以很容易地过滤包含url的tweet。如果我试图找到带有演示文稿或资源链接的tweet,这就很方便了。但是现在,我不能点击去看任何东西。我需要在我的R代码中创建可点击链接的HTML。
因此,让我回到我的微博数据帧,并做到这一点。作为提醒,下面是选择列我的表的代码。现在让我来添加列与HTML。对于鸣叫的文字,我想在最后添加一个小东西可点击这里我可以点击查看Twitter上的实际鸣叫。我决定在“空间大于-SIGN大超征”,虽然它可以是任何一个或多个字符。
如果我看一下推特的格式。看到tweet URL的格式了吗?它是twitter。com /用户名/状态/推文ID。用胶水,那就是这里的代码。如果您以前没有使用过glue,那么它是一个将文本和变量值粘贴在一起的好工具。使用一个带引号的表达式,并将希望计算的任何变量名放在大括号中。
的代码的第一行创建从状态ID和用户名的鸣叫的链接。下一行创建TweetLink,是空间大于大于链接。然后最后我创建了一条Twitter消息列包含可点击的链接。
最后,在那之后我做一个快速反应的只有新资料Tweet列来检查我的链接。有用!你可以做类似的标记网址列可点击的东西,虽然我不会是演示,以节省一点时间。
现在我将合并我的代码,这样我就不会为一条tweet创建三个新列(我这样做只是为了更容易地解释和显示代码)。我将重命名我的列,使它们更加用户友好,并生成我的最终表。
总结一下:这里我用我想要的数据从原始的tweet数据框架创建了一个新的数据框架。我正在选择一些列,然后添加推文列与可点击的链接在最后,然后选择和重命名一些列。这是我的代码,使可点击的链接从URL列。我就不详细讲了,但是你们可以暂停视频来看看。或者,点击与本视频相关的文章,这样你就可以复制和粘贴代码了。它比你想象的要复杂一些因为这一列是一个列表列;有些tweet包含多个URL。
这是我的带reactable的格式化表格。数据帧是我的第一个参数。其余部分主要是格式化和表行为。
将所有这些代码放到一个脚本中并运行它,您就得到了一个可搜索的会议标签数据库!
有一点要记住:如果您在会议期间遵从会议主题标签,你想拉足够的鸣叫让整个会议。因此,检查您的鸣叫数据帧的最早日期。如果该日期是会议开始后,要求更多的鸣叫。如果您的会议包括hashtag拥有超过18,000鸣叫 - 当我正在跟踪的消费电子展的事情发生了 - 你需要想出一些策略来获得整个集。检查出search_tweets的retryonratelimit()的参数,如果你想收集整套会议包括hashtag鸣叫追溯到6天或更少。
最后,确保在会议结束时将数据保存到本地文件中。一周后,您将不再能够通过search_tweets()和Twitter API访问这些tweet。
在奖金的文章和视频,我将演示如何把它变成一个互动的闪亮的应用程序。
这是它为这个情节,感谢收看!对于以上R提示,头向做多有R一页位点-LY削减有R做多,全部小写除了R.你也可以找到做多配合YouTube IDG技术讲座槽R播放列表 -- 在这里你可以订阅,所以你永远不会错过任何一集。希望下次再见!











受欢迎的
从IDG.tv精选视频