

如何使用tidyr的新pivot函数重新定义数据
信息世界|2019年4月5日
参见tidyr的新pivot_longer和pivot_wider函数的示例。
版权©2019Raybet2
类似的
嗨。我是IDG通信的Sharon Machlis,这里是《24集:用tidyr的新枢轴功能重塑数据》的Do More with R episode 24: data with tidyr 's new pivot functions。
我在第12集的时候报道过tidyr,但是现在有一些变化。与旧的gather()和spread()函数不同,我们鼓励您使用更直观的pivot_longer()和pivot_wider()函数。幸运的是,tidyr的作者Hadley Wickham在推特上说,gather()和spread()不会被贬低。因此,使用它们的旧代码在将来仍然可以工作。但是gather()和spread()将不再被维护,他将尝试将用户转移到pivot选项。
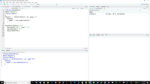
首先简单回顾一下“宽”和“长”。
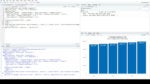
这是一个大数据集的例子。它在一行中有多个数据点,一些重要的信息(时间段)用列名而不是数据帧本身。
这里是一个长而整洁的数据集,每一行一个度量可能是这样的:
如何从第一个广泛的数据集到一个长数据集?
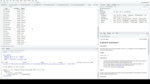
新的方法不是gather(),而是pivot_longer()。这个新功能目前可以在GitHub上的tidyr开发版本的tidyverse/tidyr存储库中找到。你可以用像remotes或pacman这样的软件包来安装它。这里我使用了remotes::install_github。
我不会运行安装,因为它已经在我的系统上,但我会加载包。
接下来,我将使用里约热内卢将来自电子表格的宽数据导入R。
Pivot_longer()使用这种格式
它有4个参数:数据帧;cols,就是你想要“主元”成为一个新列的列;names_to,新类别列的名称;以及values_to,这是您想要的新值列的名称。
真正方便的是cols参数可以使用与dplyr的select语句相同类型的列选择语法。您可以为参数中的每一列命名,但不必这样做。
在这里,我使用了一个通常的列向量名(但是没有引号)。
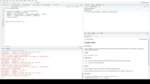
如果我不指定类别和值列的名称,它们将默认为“name”和“value”
但是我也可以使用类似于dplyr的select来编写这个语句,用于“所有列以Q开头”,或者starts_with()
这是相同的代码,但是指定了新列的名称
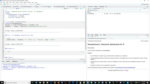
要将长数据转换为人类可读的宽数据,可以使用这种格式的pivot_wider()函数
第一个参数是数据帧。id_cols是所有你不想主元的列。它默认为您在其他两个参数中没有指定的所有内容。names_from是你想要的数据透视的列,所以每个值都是一个新列;values_from是值应该来自的列。
这里要注意:您需要显式地声明第二个参数是names_from,第三个参数是values_from,而不是预期的id_cols第二个参数的一部分。
就是这样。谢谢收看!想了解更多关于R的技巧,你可以访问https go . infoworld . com斜杠上的“用R做更多”页面,除R外都是小写字母。你也可以在IDG Tech Talk YouTube频道上找到“用R做更多”的播放列表。希望下一集再见!
我在第12集的时候报道过tidyr,但是现在有一些变化。与旧的gather()和spread()函数不同,我们鼓励您使用更直观的pivot_longer()和pivot_wider()函数。幸运的是,tidyr的作者Hadley Wickham在推特上说,gather()和spread()不会被贬低。因此,使用它们的旧代码在将来仍然可以工作。但是gather()和spread()将不再被维护,他将尝试将用户转移到pivot选项。
首先简单回顾一下“宽”和“长”。
这是一个大数据集的例子。它在一行中有多个数据点,一些重要的信息(时间段)用列名而不是数据帧本身。
这里是一个长而整洁的数据集,每一行一个度量可能是这样的:
如何从第一个广泛的数据集到一个长数据集?
新的方法不是gather(),而是pivot_longer()。这个新功能目前可以在GitHub上的tidyr开发版本的tidyverse/tidyr存储库中找到。你可以用像remotes或pacman这样的软件包来安装它。这里我使用了remotes::install_github。
我不会运行安装,因为它已经在我的系统上,但我会加载包。
接下来,我将使用里约热内卢将来自电子表格的宽数据导入R。
Pivot_longer()使用这种格式
它有4个参数:数据帧;cols,就是你想要“主元”成为一个新列的列;names_to,新类别列的名称;以及values_to,这是您想要的新值列的名称。
真正方便的是cols参数可以使用与dplyr的select语句相同类型的列选择语法。您可以为参数中的每一列命名,但不必这样做。
在这里,我使用了一个通常的列向量名(但是没有引号)。
如果我不指定类别和值列的名称,它们将默认为“name”和“value”
但是我也可以使用类似于dplyr的select来编写这个语句,用于“所有列以Q开头”,或者starts_with()
这是相同的代码,但是指定了新列的名称
要将长数据转换为人类可读的宽数据,可以使用这种格式的pivot_wider()函数
第一个参数是数据帧。id_cols是所有你不想主元的列。它默认为您在其他两个参数中没有指定的所有内容。names_from是你想要的数据透视的列,所以每个值都是一个新列;values_from是值应该来自的列。
这里要注意:您需要显式地声明第二个参数是names_from,第三个参数是values_from,而不是预期的id_cols第二个参数的一部分。
就是这样。谢谢收看!想了解更多关于R的技巧,你可以访问https go . infoworld . com斜杠上的“用R做更多”页面,除R外都是小写字母。你也可以在IDG Tech Talk YouTube频道上找到“用R做更多”的播放列表。希望下一集再见!












受欢迎的
IDG.tv的特色视频