





大家好,我是Sharon Machlis, IDG Communications数据分析编辑总监。我在这里与第12集做更多与R:重塑数据与tidyr包。
这是数据的墨菲定律:你拥有的数据并不总是在你需要的格式。而且也不是所有问题都与数据错误或空白做。有时候,你有广泛的数据需要被长;或者需要长的数据要宽。
让我们在一个示例的工作。波士顿,底特律,费城,旧金山和圣何塞(这我打电话硅谷):我会在家里价格在5个美国都市地区读取电子表格。更具体地讲,大约每2年房屋价格,开始时所有城市的100的指数在1995年这一数据运行2000年至2018年的数据。
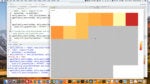
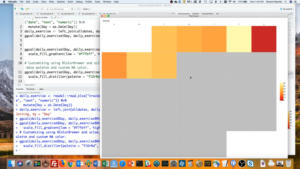
下面是电子表格:
下面是什么样子,当我与里奥包导入等。
这是一个非常人性化的格式。它有时被称为“宽”格式。每个地铁区域都有自己的专栏,你可以扫描下来的每一列,并查看该城域网的运动。
但是,如果您想用ggplot2来绘制这些数据,您需要所谓的整齐(或“长”)格式的数据。每行一个观察,列名中没有数据。因此,您可以很容易地根据城市区分ggplot2的颜色。现在,城市信息是在列名中,而不是数据本身。
再举个例子,如果我想计算哪个城市每年的指标值最高,很容易计算出每行中哪个数字最高。但是如果您想要显示哪个市区具有最高的索引值,就必须从列名中提取信息。
这是这个数据的整洁版本。
每行一个观察:季度房屋价格指数值和地铁站的区域。不容易对一个人进行扫描,但要更好地为R中分析 - 特别是tidyverse包。
如果数据的唯一版本是广义版本
你怎么得到长版本?一种方法是使用tidyr包的“收集”功能。
gather()至少接受3个参数:首先是数据帧的名称,其次是新类别列的名称——称为键。第三个是新值列的名称,叫做value。之后是您想要“收集”到新键和值列中的任何列。如果不提供任何列名,则收集所有列。在本例中,我们希望收集所有city列,而不是Quarter列。我可以用- 1 / 4来排除它。
如果我运行
你会看到我得到了一个很长的数据版本。这是收集,我的数据框架,新类别列的名称,新值列的名称,然后列出我想要收集的列或者用减号剔除那些不想收集的列。
这个版本使用ggplot2更容易绘制图形。
第一代码组是与该数据的默认ggplot折线图。只需通过添加组= MetroArea我的图表绘制每个城域网作为自己的系列,或线路。颜色= MetroArea给每个线不同的颜色。
第二个代码组添加了一点更多的自定义情节:
我选择了一个不同的主题,然后通过删除所有背景网格和y轴标签进行调整,添加标题和副标题,并将标题和副标题居中。在回到重塑之前,我想向您展示一个名为directlabels的与ggplot2一起工作的很酷的包。
我使用了刚才创建的相同的自定义绘图,但将其存储在一个名为my_customized_plot的变量中。然后在其上运行direct-dot-label函数,参数为last。文章的要点和轻微的水平对齐。看看会发生什么。
而不是图例,我有一个漂亮的标签为每一行!我很喜欢这个情节。
回到重塑。
比方说,我们开始了与这个作为整洁的数据,但想让它“宽”,以创建一个表,更易于阅读。从我们现在不得不与我们在自己的列各都市区看到,第一个版本长数据帧基本上去。对于这一点,你需要收集的(相反),这是传播()。
spread()还接受数据、键和值作为参数。在本例中,数据就是整洁的数据框架。Key是现有列的名称,您希望将其中的值转换为各自的列。这个数据是MetroArea。我们有一列metro area,我们希望每个都在自己的列中。Value是现有列的名称,其中包含应扩展到新列中的值。R可能不确定这是索引列还是四分之一列,除非我们告诉它。
我们来运行一下。
现在我们又回到了广泛的数据。
这就是本期节目的全部内容,谢谢收看!想了解更多的R技巧,请访问go.infoworld.com/morewithR的更多R视频页面。这是https go。infoworld。com斜杠+ R,除R外全小写。或者,你可以把“Do more with R”播放列表添加到你的YouTube库中。再见,希望下一集再见!
这是数据的墨菲定律:你拥有的数据并不总是在你需要的格式。而且也不是所有问题都与数据错误或空白做。有时候,你有广泛的数据需要被长;或者需要长的数据要宽。
让我们在一个示例的工作。波士顿,底特律,费城,旧金山和圣何塞(这我打电话硅谷):我会在家里价格在5个美国都市地区读取电子表格。更具体地讲,大约每2年房屋价格,开始时所有城市的100的指数在1995年这一数据运行2000年至2018年的数据。
下面是电子表格:
下面是什么样子,当我与里奥包导入等。
这是一个非常人性化的格式。它有时被称为“宽”格式。每个地铁区域都有自己的专栏,你可以扫描下来的每一列,并查看该城域网的运动。
但是,如果您想用ggplot2来绘制这些数据,您需要所谓的整齐(或“长”)格式的数据。每行一个观察,列名中没有数据。因此,您可以很容易地根据城市区分ggplot2的颜色。现在,城市信息是在列名中,而不是数据本身。
再举个例子,如果我想计算哪个城市每年的指标值最高,很容易计算出每行中哪个数字最高。但是如果您想要显示哪个市区具有最高的索引值,就必须从列名中提取信息。
这是这个数据的整洁版本。
每行一个观察:季度房屋价格指数值和地铁站的区域。不容易对一个人进行扫描,但要更好地为R中分析 - 特别是tidyverse包。
如果数据的唯一版本是广义版本
你怎么得到长版本?一种方法是使用tidyr包的“收集”功能。
gather()至少接受3个参数:首先是数据帧的名称,其次是新类别列的名称——称为键。第三个是新值列的名称,叫做value。之后是您想要“收集”到新键和值列中的任何列。如果不提供任何列名,则收集所有列。在本例中,我们希望收集所有city列,而不是Quarter列。我可以用- 1 / 4来排除它。
如果我运行
你会看到我得到了一个很长的数据版本。这是收集,我的数据框架,新类别列的名称,新值列的名称,然后列出我想要收集的列或者用减号剔除那些不想收集的列。
这个版本使用ggplot2更容易绘制图形。
第一代码组是与该数据的默认ggplot折线图。只需通过添加组= MetroArea我的图表绘制每个城域网作为自己的系列,或线路。颜色= MetroArea给每个线不同的颜色。
第二个代码组添加了一点更多的自定义情节:
我选择了一个不同的主题,然后通过删除所有背景网格和y轴标签进行调整,添加标题和副标题,并将标题和副标题居中。在回到重塑之前,我想向您展示一个名为directlabels的与ggplot2一起工作的很酷的包。
我使用了刚才创建的相同的自定义绘图,但将其存储在一个名为my_customized_plot的变量中。然后在其上运行direct-dot-label函数,参数为last。文章的要点和轻微的水平对齐。看看会发生什么。
而不是图例,我有一个漂亮的标签为每一行!我很喜欢这个情节。
回到重塑。
比方说,我们开始了与这个作为整洁的数据,但想让它“宽”,以创建一个表,更易于阅读。从我们现在不得不与我们在自己的列各都市区看到,第一个版本长数据帧基本上去。对于这一点,你需要收集的(相反),这是传播()。
spread()还接受数据、键和值作为参数。在本例中,数据就是整洁的数据框架。Key是现有列的名称,您希望将其中的值转换为各自的列。这个数据是MetroArea。我们有一列metro area,我们希望每个都在自己的列中。Value是现有列的名称,其中包含应扩展到新列中的值。R可能不确定这是索引列还是四分之一列,除非我们告诉它。
我们来运行一下。
现在我们又回到了广泛的数据。
这就是本期节目的全部内容,谢谢收看!想了解更多的R技巧,请访问go.infoworld.com/morewithR的更多R视频页面。这是https go。infoworld。com斜杠+ R,除R外全小写。或者,你可以把“Do more with R”播放列表添加到你的YouTube库中。再见,希望下一集再见!












受欢迎的
从IDG.tv精选视频