






在麻省理工人机提出数字会议,启动Nervana宣布计划为神经网络和机器学习应用程序设计和建立定制ASIC处理器,即公司的首席执行官,Naveen Rao,索赔将比图形处理器单元(GPU)快10倍。
新闻出现在谷歌上周宣布它秘密部署了其神经网络和机器学习定制的处理器在一年前的数据雷竞技电脑网站中心。该公司报告称其其定制处理器的性能提高了幅度。谷歌的性能方法和改进验证了神经内的技术战略。
+更多网络世界:有个足球雷竞技app13掌握机器学习的框架+
gpu已经成为机器学习的代名词。几年前,多伦多大学(University of Toronto)研究人工智能(AI)的杰出学生亚历克斯·克里热夫斯基(Alex Krizhevsky)证明,机器学习系统可以在价格低廉的GPU硬件上进行训练,人们对机器学习的兴趣由此爆发。在认识到GPU可以被用来加速神经网络矢量数学计算之后,Krizevsky编写了一个大规模并行GPU板来解决深度学习问题。Rao表示,gpu在超大规模移动市场的应用使得这些处理器既便宜又有效,但并没有针对机器学习进行优化。
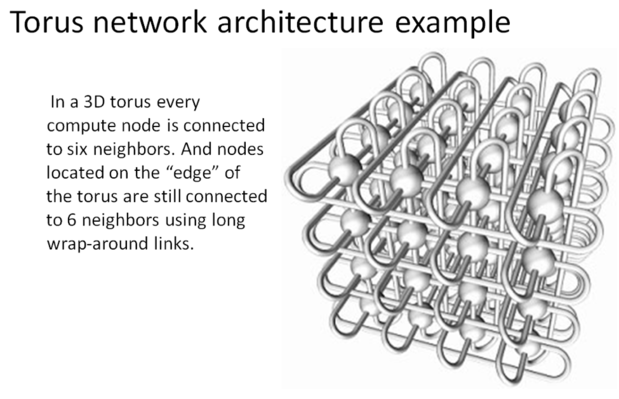
Hervana的定制ASIC称为Nervana Engine,拥有32GB的内存,每个处理器模块打包。在处理模块内,片上存储存储器互连传输速率为8Tbps。处理器模块在类似于超级计算机的圆环配置中互连,并且可以将数据存储器传输到2.4Tbps的存储器。
 富士通和riken,2009年
富士通和riken,2009年
RAO表示,机器学习系统的训练速度速度为10倍,因为可以将更大的数据模型加载到内存中并并行处理。Rao引用Antoine de Saint-Exupery在解释神经内发动机的建筑时,“完美”在没有什么时候进入的时候,但是当没有什么时候去除。“指令集减少到针对机器学习优化的一组基元,如何使用较少的指令设计RISC处理器。由于神经网络程序规定操作和内存访问,因此消除了GPU中使用的受管存储器缓存层次,加速执行和打开更多芯片空间。
Nervana发动机将由TSMC制造,具有28nm的设备尺寸,由于2017年初交付。Rao表示随后的收缩到16nm的设备尺寸可以增加性能。
霓虹灯让Nervana工程师更加控制,性能更高
Nervana开发了自己的基于python的机器学习库,名为Neon,它针对神经网络应用进行了优化,如机器翻译、图像分类、对象定位、文本分析和视频索引。Neon目前运行在运行专有微码的Nvidia图形处理器上。通过对应用层和微码层的工程控制,Nervana的工程师优化了执行时间。当Nervana引擎发布时,它将能够优化所有三个层面:应用程序、微码和硬件。
Hervana发表了NVIDIA GPU上的霓虹灯基准-by Facebook研究员Soumith Chintala-首先在机器学习表演中获得首先。当Hervana发动机交付基准时,RAO说,性能将按一份级别提高。
Nervana提供NVIDIA GPU上的霓虹灯,作为云服务,包括Monsanto。这些工作负载将于2017年转移到神经发动机。
最后一台机器学习英里
机器学习专家和程序员的数量并不能解决企业利用机器学习解决高价值问题所需的数量。经济学家最近发表了一个关于AI专家竞争的报告在硅谷的大面条公司和学术界之间。在技术人才的竞争中,企业是一个遥远的第三选择,在专家后大大寻求。
Nervana正在通过增强企业IT部门,数据科学家和统计人员的专业服务,提供上一英里的机器学习。