





R1 #显示邻接协议接口地址IP Serial4/0 point2point (7) IP Tunnel0 point2point (6) IP POS5/0.1 point2point (9) IP POS5/0.2 point2point (5) IP FastEthernet0/2 10.82.69.1 (11) IP FastEthernet0/2 10.82.69.82 (5) IP FastEthernet0/2 10.82.69.103 (5) IP FastEthernet0/2 10.82.69.220 (5) R1 #
例1 - 4显示CEF FIB表信息
R1 #显示下跳接口ip cef前缀0.0.0.0/0 12.0.0.2 Serial4/1 0.0.0.0/32收到10.0.0.0/8 10.82.69.1 FastEthernet0/0 10.82.69.0/24附加FastEthernet0/0 10.82.69.0/32收到10.82.69.1/32 10.82.69.1 FastEthernet0/0 10.82.69.82/32 10.82.69.82 FastEthernet0/0 10.82.69.121/32收到10.82.69.220/32 10.82.69.220 FastEthernet0/010.82.69.255/32收到172.0.0.0/30附加Serial4/1 172.0.0.0/32接受172.0.0.1/32 172.0.0.3/32收到172.12.12.0/24附加Loopback12 172.12.12.0/32接受172.12.12.12/32 172.12.12.255/32收到192.168.100.0/24 172.0.0.2 Serial4/1 224.0.0.0/4下降224.0.0.0/24接收R1 #
欧共体语言教学大纲的操作
CEF切换全局启用ip的英语命令global configuration mode,默认开启所有支持CEF的接口的CEF切换功能。CEF可以在每个接口的基础上启用或禁用。对于CEF交换报文,必须在入接口上使能CEF(而在出接口上使能了快速交换),因为CEF在入接口上做转发决定。使用interface configuration mode命令ip route-cache欧共体语言教学大纲的使CEF或没有在入接口上禁用CEF。
CEF的分布式版本可用于7500、7600和Cisco 12000路由器。在Cisco 12000 GSR上,CEF是默认启用的,实际上是该平台上可用的唯一交换版本,尽管在路由器架构中存在多条转发路径。
每次在启用了CEF的接口上接收到一个数据包时,CEF进程就会转发该数据包,如图所示图1-13解释下:
CEF切换开始时与其他切换方法完全相同。首先,网络接口硬件接收数据包并将其传输到I/O内存中。网络接口中断CPU,警告它在I/O内存中等待处理的入口包。IOS更新入方向报文计数器。
IOS中断软件检查包的报头信息(封装类型、网络层报头等),确定它是IP包。但是,中断软件并没有将数据包放到输入队列中进行CPU处理,而是在FIB中查找与目的地址匹配的条目。如果存在表项,中断软件从邻接表中检索预先构建的第二层报头信息,并构建该报文进行转发。最后,中断软件向出站接口发出警报。
出站网络接口硬件感知数据包,将其从I/O内存中取出,并将其传输到网络上。
如果目的地址在FIB中找不到,CEF不会返回到快速交换然后进行交换,而是直接丢弃数据包,从而导致产生的ICMP目的地不可达(type 3)产生CPU命中。快速切换对路由表没有可见性。它依赖于进程切换来动态构建快速缓存。因此,快速交换不能假定如果缓存中不存在目的地前缀,则包具有不可达的目的地。CEF则根据路由表预先建立FIB。因此,如果FIB表项不存在,则无论交换机制如何,都不会找到有效的目的前缀。这是CEF最好的特点之一;未解析的目的地不会消耗处理器负载。
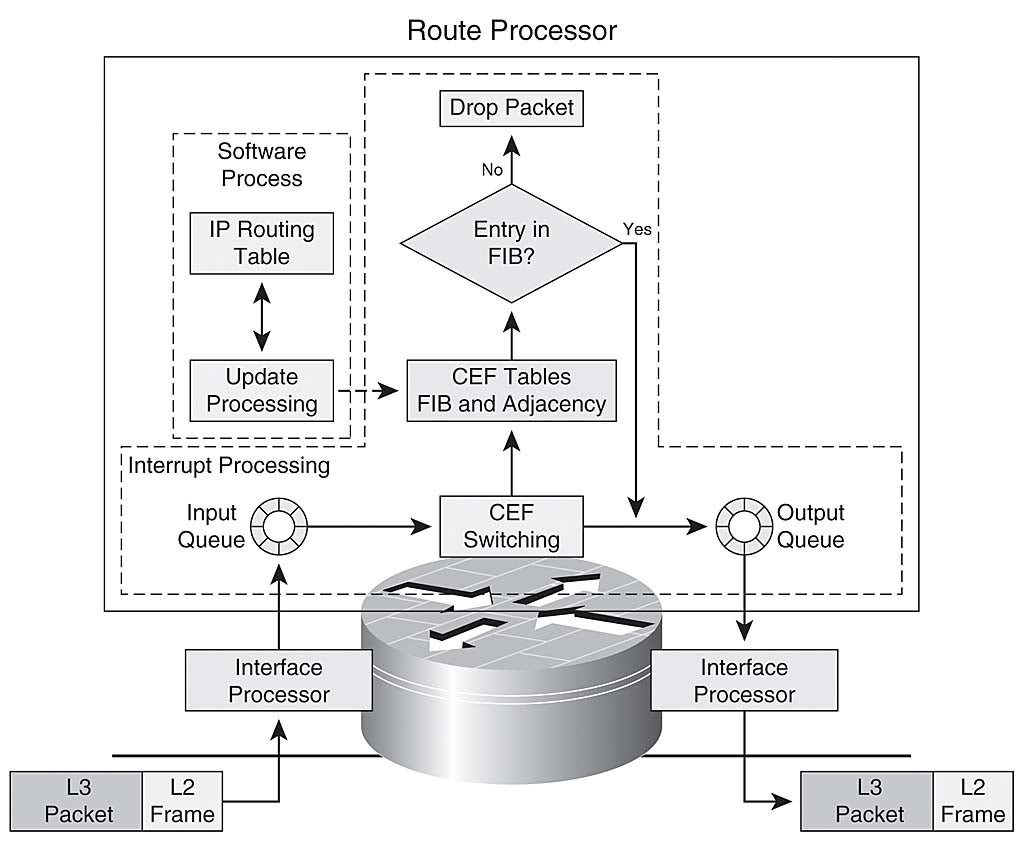
CEF切换说明
从IP流量平面的角度来看,CEF交换主要是帮助加速传输数据平面流量的转发,同时对许多其他包类型进行一致的操作。这正是构建和运行具有高包速率的高速网络所需要的。任何网络中都存在所有的流量平面和包类型,恶意包就更不用说了。所有这些包类型都必须在网络内处理,但不是所有这些包都可以被CEF交换。在这种情况下,路由器必须调用备用处理函数,这通常会影响性能。在网络中,流量平面的分类和路由器资源的保护是最关键的。让我们再从CEF切换的角度来看一下每一架交通飞机:
数据平面:开发CEF交换操作是为了加快数据平面传输流量的交付。当FIB表项存在时,这些报文被CEF交换;当FIB表项不存在时,这些报文被丢弃。与其他交换方法相比,丢弃带有未解析目的地的数据包给CEF带来了巨大的优势,因为简单地丢弃这些数据包并不需要CPU的参与。但是,您应该注意,丢弃这些数据包确实会导致生成ICMP不可达错误消息。在大多数路由器上,ICMP报文是由CPU生成的。因此,即使使用CEF切换,也可以在生成高速率的ICMP不可达消息时看到一些CPU影响。正如您将在第4章学到的,可以限制速率或禁用ICMP不可达消息生成。防止欺骗或恶意数据包滥用数据平面也有助于保护路由器和网络资源。与其他交换方法一样,处理数据平面异常包也需要额外的处理。例如,TTL = 0的报文必须被丢弃,必须生成并发送应答ICMP错误消息。 Packets with IP options may also require additional processing to satisfy the invoked option. CEF does use special adjacencies to switch these types of packets to the appropriate handlers, which means the CPU is not involved in the switching portion of the operation. Nonetheless, the CPU may be required to process these packets after CEF. When the ratio of exception packets becomes large in comparison to normal transit packets, router resources can be taxed, potentially affecting network stability. These and other concepts are explored further in Chapter 2. Chapter 4 explores in detail the concepts for protecting the data plane.
控制平面:具有传输目标的控制平面数据包是CEF切换完全像数据平面传输数据包。使用接收目的地和非IP异常报文(例如,第2层Keepalives,IS-IS等)的控制平面分组通过CEF中的特殊邻接来切换到CPU进行处理。消费其他资源以全面处理这些数据包。因此,不管调用的切换方法,CPU必须处理接收和非IP控制平面分组,可能导致高CPU利用率。高CPU利用率可能会影响CEF表的同步(例如,必须计算路由表更新时),导致流量下降。防止欺骗和其他恶意数据包影响控制平面,可能消耗路由器资源并中断整体网络稳定性是至关重要的。第5章详细探讨了这些概念。
管理平面:带有传输目的地的管理平面数据包与数据平面传输数据包完全一样,是CEF交换的。接收目的地的管理平面报文通过CEF中特殊的邻接关系交换到CPU进行处理。需要消耗额外的资源来完全处理这些数据包并提供适当的网络管理服务。管理平面流量不应包含IP异常报文(MPLS OAM也是例外),但可以包含非IP(二层)异常报文(一般为CDP报文)。正常情况下,管理平面流量对CPU性能的影响较小。一些管理操作(例如频繁执行SNMP轮询或打开调试操作)或使用NetFlow可能会导致较高的CPU占用率。高CPU利用率可能会影响CEF表的同步(例如,必须计算路由表更新时),导致流量下降。由于管理平面的流量是由CPU直接处理的,因此滥用的机会使得管理平面安全的实现变得至关重要。第六章详细探讨了这些概念。
服务的飞机:业务平面报文一般需要路由器进行特殊处理。例如,执行某些封装功能(例如GRE、IPsec或MPLS VPN),或执行某些QoS或策略路由功能。这些操作中有些可以通过CEF切换来处理,有些则不能。如果CEF不支持某个特性或封装,数据包就会被传递到下一交换层(对于大多数路由器来说,这是快速交换),下一交换层会使用缓存来交换数据包。如果它不能在中断级交换,包被放置到IP处理队列中直接进行CPU处理。由于不支持的特性,CEF无法切换报文。此时,业务平面包可能会对CPU利用率产生很大影响。因此,主要关注的是通过防止欺骗或恶意数据包影响CPU来保护服务平面的完整性。第7章详细探讨了这些概念。
一般IP路由器架构类型
现在,我们已经回顾了IOS中可用的主要交换方法,并描述了各种IP流量平面对其操作和性能的影响,我们有必要看看Cisco路由器中使用的各种硬件架构。尽管大多数Cisco路由器都实现了前一节中描述的所有交换方法,但也有一些没有。此外,硬件的变化导致每个IP通信平面的性能水平不同。因此,理解网络中插入的每个平台的性能包络非常重要。本节特别关注恶意流量影响路由器硬件架构的方式。
性能的提高和对集成服务的需求推动了路由器硬件的重大变化。大多数思科路由器只使用一个活动路由处理器,即使安装了多个。因此,处理在一个中心位置完成。一些路由器采用专用ASIC硬件来加速交换性能。还有一些使用分布式硬件架构来实现最高的转发速率。
以下部分提供了思科路由器目前使用的基本硬件架构的总体概述。本文对这些体系结构进行了足够详细的介绍,以便更好地理解各种IP通信平面如何影响它们的性能。许多优秀的参考文献对路由器架构提供了更深入的见解。检查”进一步的阅读,以获得具体的建议。
集中CPU-Based架构
最初的Cisco路由器以及随后的几代企业级路由器所使用的架构是基于中央处理器的设计。目前在使用的这类路由器包括800、1600、1700、2500、2600、3600、RPM-PR和3700系列型号。寿命较长的7200系列和较新的1800、2800和3800系列集成服务路由器(ISR)也使用基于中央处理器的体系结构。
集中式CPU架构依赖于单个CPU来执行路由器所需的所有功能。这包括以下职能:
支持所有网络功能,如运行和维护路由协议和缓存状态、链路状态、接口和全局计数器、ICMP (error packet)生成等网络控制功能
支持所有的报文转发和处理功能,包括应用转发过程中可能应用到报文的所有业务,如访问列表、NAT、QoS等
支持所有内务功能,如服务配置和管理功能,包括命令行配置,SNMP和syslog支持,以及其他设备管理功能
所有这些(和其他)功能都在思科IOS软件中处理。思科IOS是一个单片操作系统;所有软件模块都在构建时静态编译和链接,在单个地址空间内运行到完成模型。在这种模型中,一个函数的错误可能导致其他函数的中断。在前一节中,您了解了三种不同的切换方法,每种方法都有不同的交互级别,因此对CPU的影响也不同。
一个典型的集中式cpu架构显示在图1 - 14.总线体系结构、内存大小和速度、CPU处理器性能的进步,以及专门的、面向任务的芯片组的增加,导致了路由器整体性能的改善。然而,即使有了这些改进和添加,考虑到基于cpu的体系结构的处理约束,基于cpu的集中式设备在总体性能上仍然是有限的。
{kind=link}