





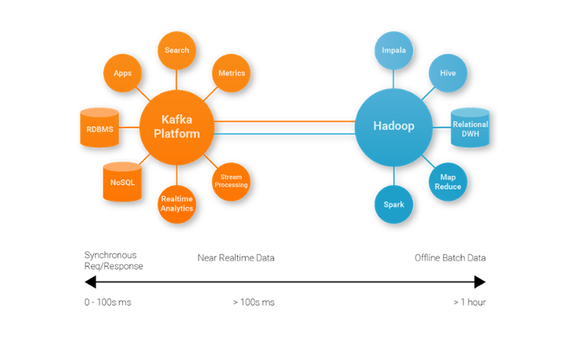
分析常常被认为是与大数据相关的最大挑战之一,但即使在这一步发生之前,数据也必须被吸收并提供给企业用户。这就是Apache Kafka发挥作用的地方。
最初由LinkedIn开发,卡夫卡是一个用于管理来自网站、应用程序和传感器的实时数据流的开源系统。
从本质上说,它充当一种企业“中枢神经系统”,收集诸如用户活动、日志、应用程序指标、股票报价器和设备仪表等大量数据,并使其成为企业用户使用的实时流。
RedMonk的联合创始人和首席分析师Stephen O' grady说,Kafka经常被拿来与ActiveMQ或RabbitMQ等技术进行比较,以实现本地实现,或者与Amazon Web Services为云客户提供的Kinesis进行比较。
O'Grady补充说:“它变得越来越引人注目,因为它是一个高质量的开源项目,但也因为它处理高速信息流的能力在服务物联网等工作负载方面的需求越来越大。”
自从在领英(LinkedIn)怀上卡夫卡以来,她获得了来自LinkedIn的高调支持公司比如Netflix、Uber、思科和高盛。上周五,IBM宣布将通过Bluemix平台提供两项基于kafka的新服务,这给微软带来了新的推动力。
IBM新推出的流媒体分析服务旨在每秒分析数百万个事件,实现亚毫秒级的响应时间和即时决策。IBM Message Hub(现在是beta版)为云应用程序提供了可扩展的、分布式的、高吞吐量的异步消息传递,可以选择使用REST或Apache Kafka API(应用程序编程接口)与其他应用程序通信。
Kafka是在2011年开源的。去年,卡夫卡的三位创造者创立了Confluent,这是一家致力于帮助企业在生产中大规模使用it技术的初创公司。
Kafka的创建者之一、Confluent的联合创始人尼哈·纳克海德(Neha Narkhede)说:“在LinkedIn的爆炸式增长阶段,我们无法跟上不断增长的用户群和可以用来帮助我们改善用户体验的数据。”
“Kafka可以让你在整个公司内移动数据,并在几秒钟内让需要使用数据的人获得持续自由流动的数据流,”Narkhede解释说。“而且规模很大。”
她说,LinkedIn的影响是“转型的”。今天,LinkedIn仍然是Kafka最大的生产部署;它每天超过1.1万亿条消息。
与此同时,Confluent通过订阅方式提供先进的管理软件,帮助大公司运行Kafka的生产系统。Narkhede说,该公司的客户中有一家大型零售商和"美国最大的信用卡发行商之一"。雷竞技比分
她说,后者正在使用实时欺诈保护技术。
Kafka是“一个非常快的消息总线”,它擅长于快速集成大量不同类型的数据,451 Research的分析师Jason Stamper说。“这就是为什么它会成为最受欢迎的选择之一。”
他指出,除了ActiveMQ和RabbitMQ,另一个提供类似功能的产品是Apache Flume;风暴和火花流在许多方面也是相似的。
Stamper补充说,在商业领域,Confluent的竞争对手包括IBM的InfoSphere Streams、Informatica的Ultra Messaging Streams Edition和SAS的Event Stream Processing Engine (ESP),以及Software AG的Apama、Tibco的StreamBase和SAP的Aleri。较小的竞争对手包括DataTorrent, Splunk, Loggly,Logentries、X15软件、相扑逻辑和Glassbeam。
在云计算方面,AWS的Kinesis流处理服务“还有一个额外的好处,就是可以与红移数据仓库和S3存储平台相集成,”他说。
Teradata新宣布的侦听器弗雷斯特研究公司(Forrester Research)副总裁兼首席分析师布莱恩霍普金斯(Brian Hopkins)指出,它也是一个竞争者,而且总部也设在卡夫卡。
霍普金斯说,一般来说,实时数据有一个明显的趋势。
他说,大约在2013年之前,“大数据都是被塞入Hadoop的大量数据。”“现在,如果你不这样做,你就已经落后于权力曲线了。”
他说,如今,来自智能手机和其他来源的数据让企业有机会与消费者进行实时互动,并提供相关体验。而这又依赖于更快地理解数据的能力。
“物联网就像是移动领域的第二波浪潮,”霍普金斯解释说。“每个供应商都在为海量数据做准备。”
因此,技术也在相应地进行调整。
“到2014年,一切都是关于Hadoop的,然后就是Spark,”他说。“现在,是Hadoop、Spark和Kafka。在这个现代分析体系结构中,这三家公司在数据摄取管道中地位相当。”