






随着数雷竞技电脑网站据中心被要求处理大量输入各种前沿应用程序的非结构化数据,FPGAs的未来看起来很光明。
因为fpga,或现场可编程门阵列,本质上是芯片可以通过编程来实现,制造后,作为定制加速器工作负载包括机器学习、复杂的数据分析、视频编码、和基因组学——产生深远影响的应用程序通信,网络、医疗保健、娱乐业和许多其他企业。
这样的应用程序可以进行并行处理,这是FPGAs的一个重要特性,也可以根据工作负载的变化动态重新配置,以处理新特性。
几十年来,Xilinx一直在与竞争对手Altera(现在是英特尔的一部分)争夺FPGAs的技术领先地位。现在,Xilinx推出了一个新的产品类别——自适应计算加速平台(ACAP)。
什么是ACAP?
Xilinx周一宣布,该类别的第一个产品系列代号为Everest,将于今年推出(设计完成),并于明年向客户发货。很难说这是当前fpga的一种渐进进化,还是更激进的东西,因为该公司正在公布一种架构模型,其中省略了很多技术细节,比如该芯片将使用何种应用程序和实时处理器。
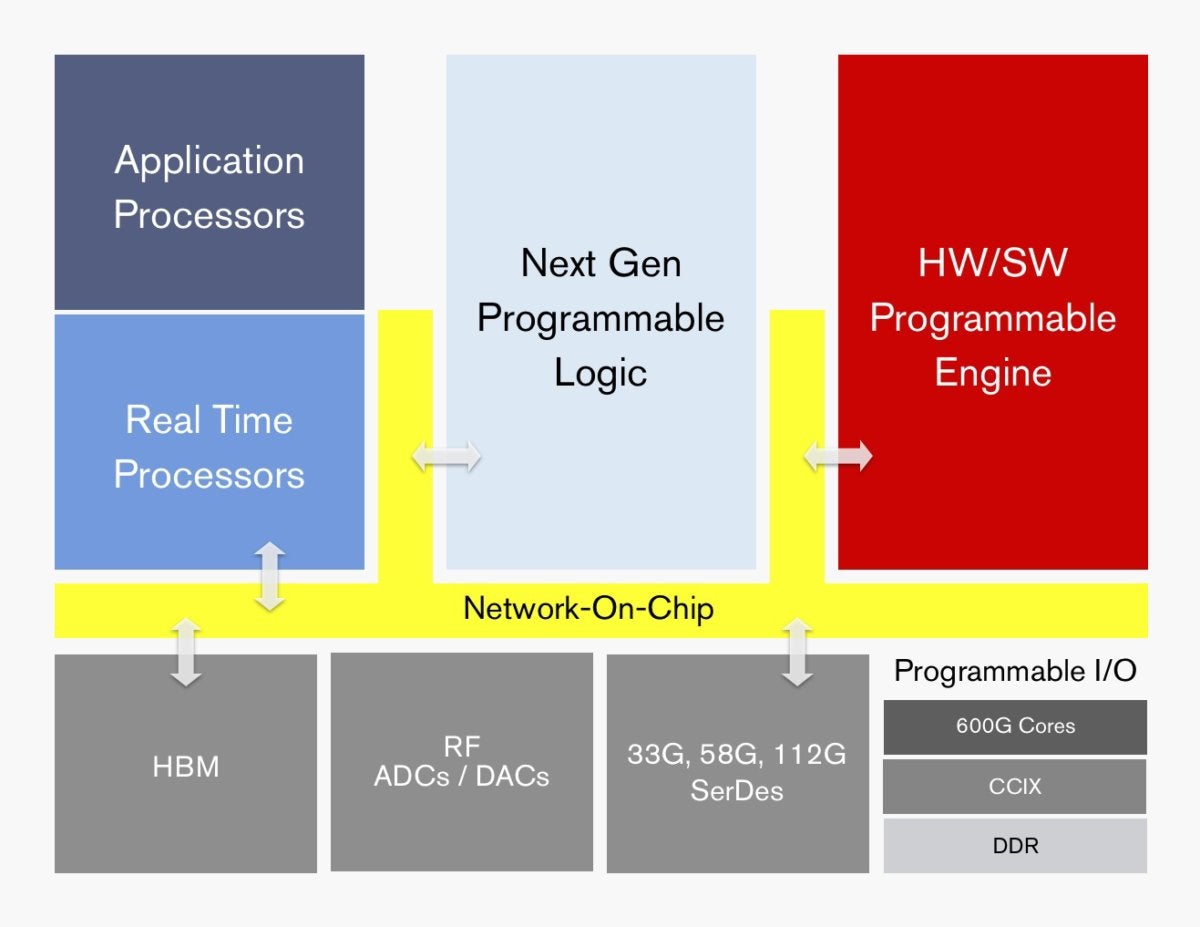
不过,我们所知道的这些特性是很重要的。Everest将合并一个NOC(芯片上的网络)作为标准功能,并使用CCIX(用于加速器的高速缓存相干互连)互连结构,这两种结构目前都没有出现在FPGAs中。
Everest将提供硬件和软件可编程性,并将成为市场上首批使用7nm制程技术(在本例中为TSMC制程技术)的集成电路之一。制造工艺技术越小,处理器上的晶体管密度越大,这就导致了成本和性能效率。
虽然在制造工艺的命名和英特尔和台积电的制造工艺的相对优点方面存在争议,但基本的想法是,7nm的尺寸大约是当前一代fpga的一半,每平方毫米的性能是四倍。与英特尔公司(前身为Altera公司)的晶体管相比,埃佛勒斯峰设备将拥有高达500亿个晶体管Stratix 10 fpga它采用14nm制程,拥有300亿个晶体管。
 赛灵思公司
赛灵思公司
Xilinx使用其ACAP技术的第一个产品系列代号为Everest,由TSMC process technology开发。
“我们真的觉得这是一个不同的产品类别,”最近被任命为Xilinx首席执行官彭文迪说。在过去的四年里,Xilinx已经投入了大约10亿美元,并派出了1500名工程师参与该项目。
Xilinx目前声称,相对于基于CPU或gpu的系统,它的fpga能够根据不同的工作负载进行定制,从而将处理速度提高了40倍,将处理速度提高了10倍,将处理速度提高了10倍,将基因组学速度提高了100倍。该公司表示,ACAPs将进一步加快人工智能推理速度,比目前的FPGA架构提高20倍,并将5G通信速度提高4倍。
fpga传统上提供了一系列可配置的逻辑块,通过可编程互连连接。多年来,fpga的重新配置都是通过硬件描述语言(HDLs)完成的,但芯片开发人员已经开始调整设备的架构,以支持使用更高级别的软件编程语言。
Xilinx最近发布的全可编程SoC(片上系统)将集成到产品中的基于arm的处理器的软件可编程性与FPGA的硬件可编程性相结合。
“我们一直在转型,但如果你愿意,ACAP是一个转折点,”彭说。“尽管之前FPGAs是灵活和适应性强的,但它的水平要高得多,是的,我们最近开始让人们在软件层面上进行更多的开发,但我们要用这类产品来做的程度要高得多。”这使得它比我们之前看到的有了巨大的进步。”
使用高级软件编程语言
Xilinx表示,软件开发人员将能够使用C/ c++、OpenCL和Python等工具与Everest一起工作。Everest还可以使用Verilog和VHDL等HDL工具在硬件、寄存器传输级别(RTL)上进行编程。
Moor Insights & Strategy的分析师卡尔·弗罗因德(Karl Freund)认为,攀登珠穆朗玛峰更多的是Xilinx战略的演变,而不是一个激进的步骤,但他强调,珠峰在硬件和软件方面的进步是重大的。
Freund说:“这确实是一个新的范畴,但使它成为一个新的范畴的不仅仅是芯片,而是芯片、软件、图书馆,甚至是网络开发模型。”
他说:“他们在软件堆栈上投入了大量资金,所谓的加速堆栈可以让你更快地部署FPGA解决方案,因为他们基本上提供了一些标准化的库、工具、算法和IP块,你可以在FPGA上挑选和部署它们。”
Xlinx表示,除了尚未指定的多核SoC(芯片上的系统)之外,Everest还将提供PCIe以及CCIX互连支持、多模式以太网控制器、用于安全和电源管理的芯片上控制块,以及可编程I/O接口。它还包括不同类型的SerDes -收发器,可以将并行数据转换为串行数据,反之亦然。具体来说,它将提供33Gbps NRZ(不归零),58Gbps PAM-4(脉冲幅度调制)和112G PAM-4 SerDes。通常,PAM机制提供的带宽比NRZ多。
Xilinx说,某些Everest芯片还将提供高带宽内存(HBM),或可编程ADC(模拟-数字)和DAC(数字-模拟)转换器。
在网络芯片上,相干缓存是关键的区分器
Xilinx说FPGAs和ACAPs之间的一个关键区别是NOC,它连接设备的各个子系统,如多个处理器和I/O元素。到目前为止,FPGAs还没有系统级的noc,开发人员必须通过芯片的可编程逻辑创建连接基础设施。“你仍然可以通过可编程逻辑对子系统进行编程,但一般来说,你不会得到相同的性能特征,”彭说。
另一个关键元素是CCIX。弗罗因德说:“具有革命性的是,它的缓存一致性。”“这是你第一次能够使用标准的网络协议,用cache-coherent加速器来构建一个系统,而这在目前的行业中是不存在的。”
CCIX是美国国际贸易委员会正在开发的一套规范CCIX财团解决缓存一致性问题,或者在尝试修改相同的内存空间或处理过时的数据副本时如何确保不同的cpu不冲突。
珠穆朗玛峰的一大目标是人工智能。没人指望珠穆朗玛峰能与英特尔(Intel) cpu和英伟达(Nvidia) gpu的单马力竞争。英特尔cpu和英伟达gpu被用来“训练”tb级的数据集,以在庞大的、100层深的机器学习神经网络中工作。
但弗罗因德指出,珠穆朗玛峰的适应性,就像传统的FPGAs一样,使它成为“推断”的理想场所,或者实际上将神经网络用于实际情况。这是因为神经网络的每一层都应该以尽可能少的精度进行处理,以节省时间和精力。与具有固定精度的cpu不同,FPGAs可以编程处理神经网络的每一层,一旦建立,适合该层的精度最低。
边缘设备是主要目标
尽管Xilinx表示其主要目标是数据中心,但edge设备和物联网最终可能会成为珠峰的亮点。雷竞技电脑网站机器学习应用程序将越来越多地集成到边缘设备中,与大型服务器相比,这些设备的功耗非常有限,这使它们成为fpga的理想选择。
微软是第一个宣布将FPGAs部署到其公共云基础设施的主要云提供商,去年,微软对fpga在人工智能领域的应用投下了信任票,宣布将在脑波项目中使用fpga深度学习的平台。它使用的是Xilinx的宿敌Intel/Altera公司的Stratix 10 fpga,但这有助于巩固使用fpga进行人工智能推断的想法。
随着Xilinx和英特尔转向更小的制造工艺技术,两家公司之间的持续竞争将会结束。英特尔已经宣布了代号为猎鹰梅萨的FPGAs一些业内人士表示,该技术将提供与台积电7nm工艺相当的晶体管密度。
随着珠穆朗玛峰和猎鹰台地可能在2019年推出,它看起来像FPGAs——或者在Xilinx的例子中,ACAPs——将在计算趋势中扮演比以往更重要的角色。