11个开源工具,充分利用机器学习
通过这些不同的、易于实现的库和框架来利用机器学习的预测能力















11个用于充分利用机器学习的开源工具
垃圾邮件过滤功能,脸部识别,推荐引擎 - 当你有,你想进行预测分析或模式识别大型数据集,机器学习是要走的路。这门科学,在计算机培训了来自学习,分析和数据采取行动而不被明确地编程,已飙升在其原有的学术和高端编程界的回廊后期外的利益。
这种上升的普及不仅是由于硬件不断增长的更便宜和更强大,而且免费的软件,使机器学习更容易在单个机器和规模化同时实现增殖。机器学习库,意味着有多样性可能是可用的选项,无论你喜欢什么语言或环境。
这11机器学习工具提供了单独的应用程序或整个框架,如Hadoop的功能。有些人比其他人更通晓多国语言:Scikit,例如,是专门为Python,而幕府运动接口,多国语言,从通用到特定领域。
Scikit学习
Python已经成为一去到编程语言,数学,科学和统计数据,因为它易于采纳和库可用于几乎任何应用的广度。NumPy的,SciPy的,和matplotlib - - 对数学和科学工作的基础上现有的几种Python包顶Scikit学习利用此广度。所得文库可任意用于交互式“工作台”应用程序或嵌入其他软件和再利用。该套件是一个BSD许可下可用,所以它是完全开放的和可重复使用。
项目:scikit-learn
GitHub:https://github.com/scikit-learn/scikit-learn

协议框架/ AForge.net
雅阁,对于.NET机器学习和信号处理架构,在同样的一个以前的项目的延伸,AForge.net。顺便说一下,“信号处理”在这里指的是一系列针对图像和音频的机器学习算法,比如无缝拼接图像或执行人脸检测。包括一套视觉处理算法;它对图像流(如视频)进行操作,可用于实现跟踪移动对象等功能。Accord还包括一些提供更传统的机器学习功能的库,从神经网络到决策树系统。
项目:协议框架/ AForge.net
GitHub:https://github.com/accord-net/framework/
MLlib
Apache自己的Spark和Hadoop的机器学习库,MLlib拥有的色域常见的算法和有用的数据类型,旨在以速度和规模运行。正如您对任何Hadoop项目所期望的那样,Java是在MLlib中工作的主要语言,但是Python用户可以将MLlib与NumPy库(也在scikit-learn中使用)连接起来,而Scala用户可以编写针对MLlib的代码。如果设置Hadoop集群不切实际,可以在不使用Hadoop的情况下在Spark之上部署MLlib——而且可以在EC2或Mesos中部署。
另一个项目,MLbase,建立在MLlib的顶部使推导结果更容易。用户不需要编写代码,而是通过声明性语言(即SQL)进行查询。
项目:MLlib

H2O
0xdata的H2O算法适合于业务流程——例如,欺诈或趋势预测——而不是图像分析。H2O可以独立地与HDFS商店交互,在YARN之上,在MapReduce中,或者直接在Amazon EC2实例中。Hadoop专家可以使用Java与H2O交互,但是该框架还提供了针对Python、R和Scala的绑定,提供了与这些平台上所有可用库的交叉交互。
项目:H20
GitHub:https://github.com/0xdata/h2o
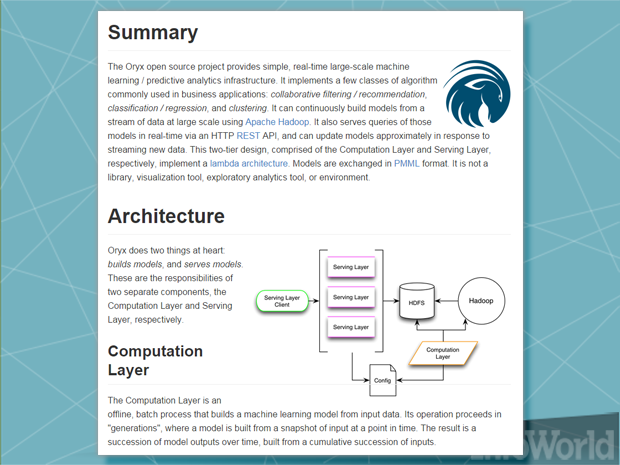
Cloudera的羚羊
另一种专为Hadoop的机器学习项目,羚羊配备的创造者的礼貌Cloudera的Hadoop发行版。标签上的名字并不是唯一让Oryx与众不同的细节:Per Cloudera强调分析实时流数据通过Spark项目,Oryx被设计成允许在实时流数据上部署机器学习模型,支持像实时垃圾邮件过滤器或推荐引擎这样的项目。
这个项目的一个全新版本,暂定名为Oryx 2,正在开发中。它使用像Spark和Kafka这样的Apache项目来获得更好的性能,并且它的组件是按照更松散耦合的线构建的,以进一步验证未来。
项目:Cloudera的羚羊
GitHub:https://github.com/cloudera/oryx
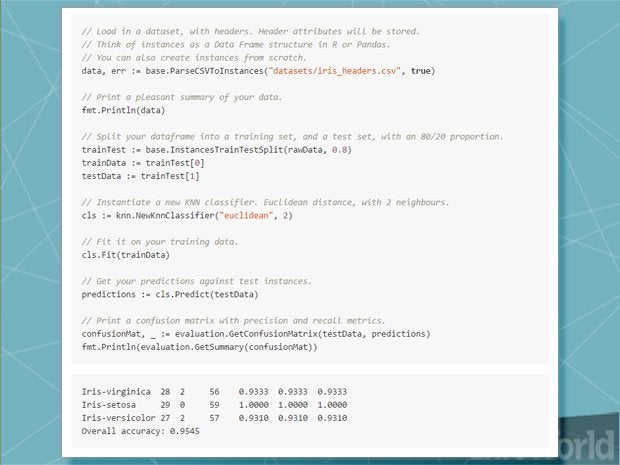
GoLearn
谷歌的Go语言已经在野外只有五年,但开始广泛使用由于库的成长集合。GoLearn成立是为了解决缺乏围棋的所有功能于一身的机器学习库;我们的目标是“简单搭配定制”,根据开发者史蒂芬Witworth。The simplicity comes from the way data is loaded and handled in the library, since it’s patterned after SciPy and R. The customizability lies in both the library’s open source nature (it’s MIT-licensed) and in how some of the data structures can be easily extended in an application. Witworth has also created用于元音字母Wabbit库的Go包装器,库之一,在幕府工具箱中。
项目:GoLearn
GitHub:https://github.com/sjwhitworth/golearn

CUDA-Convnet
到目前为止,大多数人都知道gpu如何能够比cpu更快地处理某些问题。但应用程序不会自动利用GPU加速;它们必须被专门写下来。CUDA- convnet是一个用于神经网络应用的机器学习库,用c++编写,以利用Nvidia的CUDA GPU处理技术(至少需要费米一代的CUDA板)。对于使用Python而不是c++的用户,生成的神经网络可以保存为Python pickle对象,从而可以从Python访问。
注意,这个项目的原始版本已经不再被开发,但是已经被重新开发为一个后续的CUDA-Convnet2,它支持多个gpu和开普勒生成的gpu。一个类似的项目,Vulpes,已经写在F#和与.NET Framework通常工作。
项目:CUDA-Convnet
ConvNetJS
顾名思义,ConvNetJS提供神经网络的机器学习库,用于在JavaScript中使用,便于使用浏览器作为数据工作台。一个NPM版本也可以使用Node.js的那些,和图书馆的目的是使JavaScript的异步的正确使用 - 例如,训练操作可以给出一个回调,一旦他们完成执行。的演示大量的例子包括,太。

更多的信息世界”的幻灯片
版权©2014Raybet2
![有个足球雷竞技app网络世界[幻灯片]- 2018年十大超级计算机[幻灯片01]](https://images.idgesg.net/images/article/2018/06/nw_ss_top_ten_supercomputers_2018_slide_01_1200x800-100762093-medium.3x2.jpg)